无监督学习与主成分分析
序
在之前的文章中,我讲了很多监督学习的算法(线性模型,SVM,决策树,神经网络等),那么接下来,我们要开始接触无监督学习了。首先,我们先说下相关概念。
无监督学习
与监督学习不同,在无监督学习中,学习算法只有输入数据,并且从数据中提取需要的知识。而其中有两种常用类型:数据集变换和聚类。
无监督变换是创建数据新的表示的算法,与数据的原始表示相比,新的表示可能更容易被人或其它机器学习算法所理解。而无监督变换的一个常见应用就是降维,它接受包含许多特征的数据的高维表示,并找到表示该数据的一种新的方法,用较少的特征就可以概括数据信息的重要特性。降维的一个常见应用是将数据降为二维之后进行可视化。(PS:这里的降维和“降维打击”里面的降维是两回事。。。)
无监督变换的另一个应用是找到”构成“数据的各个部分。这方面的一个例子就是对文本文档集合进行主题提取。
而与之相反,聚类算法就是将数据划分成不同的组,每组包含相似的物项。譬如说人脸识别,可以将相同的某个人的照片分在一组。
实际上,无监督学习的一个主要挑战就是评估算法是否学习到了有用的东西。因为无监督学习一般用于不包含任何标签信息的数据,所以我们不知道正确的输出应该是什么。因此很难判断一个模型是否”表现良好“。通常来说,评估无监督算法结果的唯一方法就是人工检查。
PS:博主之前在58同城做过微聊审核相关的工作。整体的审核流程大致就是用机器学习建立一个模型,去评估用户有没有说违规的话,之后随机抽取模型的审核结果,再进行人工复审。当复审的错误率达到某个阈值的时候,就需要向技术部门阐明情况,提出修改模型的要求了。
因此,如果数据科学家想要更好地理解数据,那么无监督算法通常可用于探索性的目的,而不是作为大型自动化系统的一部分(这点与监督学习是不同的)。因此无监督算法的另一个常见应用就是作为监督算法的预处理步骤。
主成分分析(PCA)
前面说过,利用无监督学习进行数据变换可能有很多种目的。最常见的就是可视化,压缩数据(降维),以及寻找信息量更大的数据表示以用于进一步的处理。为了实现这些目的,最简单也是最常用的一种算法就是主成分分析(PCA)。
PS:接下来要说理论的东西了,很枯燥,但是希望各位朋友可以耐心的看完,下面的内容对于算法的理解很有帮助。
主成分分析(PCA)是一种旋转数据集的方法,旋转后的特征在统计上不相关。在做完这种旋转之后,通常是根据新特征对解释数据的重要性来选择它的一个子集。
接下来,我用通俗一点的话来解释下:
首先,模型就是数据集所表现出来的信息的集合体或者说构成体。通常,在机器学习的过程中,特征的个数过多会增加模型的复杂度。而我们所希望的理想状态就是用最少的特征表示数据集最多的信息。
在许多情形下,特征之间是有一定的相关关系的(如线性相关:一个特征可以用另一个特征线性表示)。而当两个特征之间有一定的相关关系时,可以理解为两个特征所反映的此数据集的信息有一定的重叠。(譬如特征x和特征y,其中y=a*x+b)。
而主成分分析就是对于原先数据集的所有特征进行处理。删去多余的重复的特征,建立尽可能少的特征,使得这些新特征两两不相关。并且这些新特征在反映数据集的信息方面尽可能保持原有信息。
数据来源
来自于kaggle的一份关于心脏病患者分类的数据集:https://www.kaggle.com/ronitf/heart-disease-uci
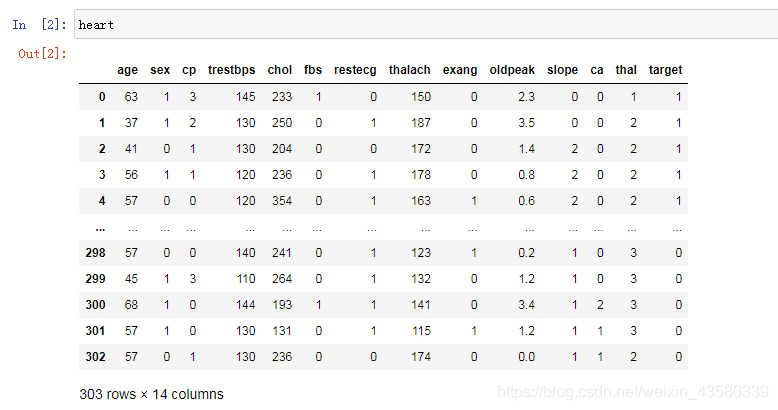
这份数据集并不大,只包括303份数据样本(该数据不包含空值)。其中数据特征包括患者年龄,性别,心率,血糖量,血压等13个维度以及分类目标-target。而我们所需要做的,就是依照这些特征值来进行建模,从而依照模型的某种趋势来判断患者心脏是否健康。
PCA实际应用-降维
1.数据导入
1 | |
老规矩,上来先依次导入建模需要的各个模块,并读取文件。
2.标准化
由于PCA的数学原理是依照方差最大的方向来去标记主成分,所以我们先对数据进行标准化,使得各个维度的方差均为1.所以我们先用StandardScaler来对数据进行缩放,代码如下:
(PS:具体实现原理及过程就不再赘述了,不了解的朋友可以看下python机器学习之数据预处理与缩放)。
1 | |
注意别忘了把数据集中的分类目标提取出来(heart.drop(["target"],axis=1)),分类目标是我们的分类目的或者说结果,而这里的标准化是不针对分类目标的。
3.PCA拟合转换
学习并应用PCA变换与应用预处理变换一样简单,代码如下:
1 | |
为了调整降低数据的维度,我们需要在创建PCA对象时指定想要保留的主成分个数(n_components=2)。之后将PCA对象实例化,调用fit方法找到主成分,再调用transform来旋转并降维。默认情况下,PCA仅变换数据,但保留所有的主成分。
我们来看下变换前后的数据规模:
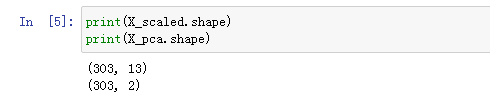
可以看出数据由之前的303x13,变成了303x2,样本数量没有变化,特征维度由之前的13个变成了2个。
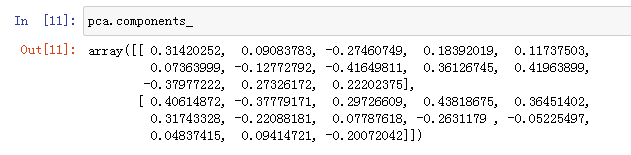
在拟合过程中,主成分被保存在components_属性中,其中每一行对应于一个主成分,它们按照重要性排序(第一主成分排在首位,以此类推)。列对应于PCA的原始特征属性。
PCA实际应用-高维数据可视化
正如我们之前所说的,PCA的另一个应用就是将高维数据可视化。要知道,对于有两个以上特征的数据,我们是很难绘制散点图的,譬如说上面包含13个维度的心脏患病数据。但是,我们可以用散点图画出PCA变换之后的两个主成分,并着色分类,代码如下:
1 | |
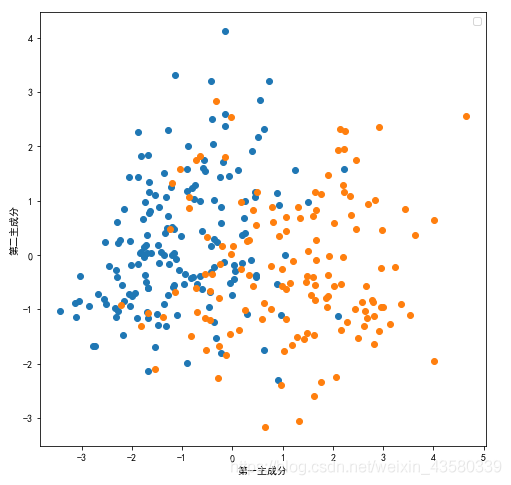
上面的散点图绘制了第一主成分和第二主成分的关系,然后利用类别信息对数据点进行着色。这让我们相信,即使是线性分类器(在这个空间中学习一条直线)也可以在区分这两个类别时表现的相当不错。
在这里提醒大家一点,要注意pca是一种无监督的方法,在旋转方向时没有用到任何类别信息。它只是观察数据中的相关性。
小结
缺点
pca有一个缺点,就是通常不容易对图中的两个轴进行解释。虽然主成分是原始特征的组合,但这些组合往往非常复杂,我们可以用热力图表现出来:
1 | |
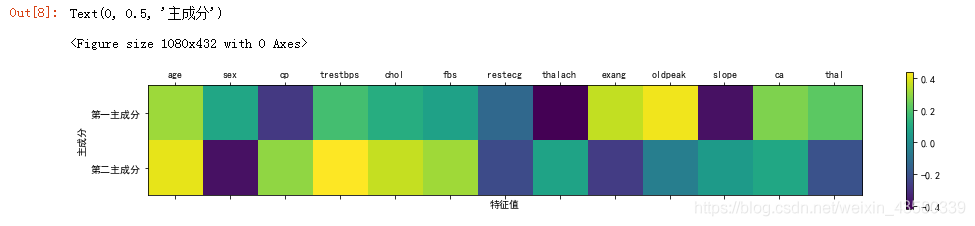
PS:横坐标轴是13个特征维度
上图可以看出每个主成分均是由13个特征值组成的,还展现出了各个特征对于成分构成的重要性(颜色越深越重要),但是我们却无法明确的指出这些特征如何构成主成分的。
优点
至于优点,我们从之前的散点图便可以看出来,那就是用简单的模型便可以对数据进行分类。通常来说,SVM核向量算法要比普通的线性模型算法Logistic更为复杂,且模型精度要更高一些。(SVM与Logistic的原理之前有在其他的文章中讲过,感兴趣的朋友可以点击链接去看一下,这里就不多做解释了。)
那么为了突出刚才提到的优点,接下来我们用svm对没有经过pca变换的数据进行建模:
1 | |

再利用Logistic算法对变换后的数据进行建模:
1 | |
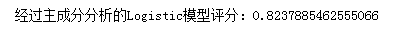
从上面的结果对比便可以看出pca的优点,那就是在最大限度地保留了数据集的信息状态的条件下,它将原本复杂的数据集,转变为了更容易训练的低维度数据级,提高了模型的训练精度。
有很多地方做的不是很好,欢迎网友来提出建议,也希望可以遇到些朋友来一起交流讨论。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!