无监督学习——聚类评估
序
在用聚类算法时,其挑战之一就是很难评估一个算法的效果好坏,也很难比较不同算法的结果.在讨论完k均值,凝聚聚类和DBSCAN背后的算法之后,下面我们来说一下如何对聚类进行评估.
用真实值评估聚类
有一些指标可用于评估聚类算法相对于真实聚类的结果,其中最重要的是调整rand指数和归一化互信息。二者都给出了定量的度量,其最佳值为1,0表示不相关的聚类(虽然ARI可以取负值)。
下面我们使用ARI来比较k均值,凝聚聚类和DBSCAN算法。
PS:数据集是make_moons,之前有在DBSCAN,k均值聚类,凝聚聚类中使用过,感兴趣的可以点开链接看一下,这里就不再赘述了。
首先,我们先导入数据集,并进行标准化(不了解标准化的可以点击链接浏览一下):
1 | |
之后,依次导入各类算法,并设立一个随机簇,作为参考:
1 | |
最后,我们用”K均值聚类”,”凝聚聚类”,”DBSCAN”依次进行聚类操作,并把结果汇总成一个表格:
1 | |
结果如下所示:
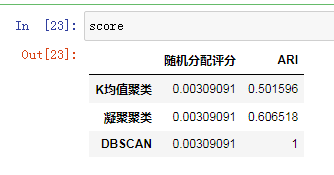
调整rand参数给出了符合直觉的结果,随机簇分配的分数约等于0,而DBSCAN(完美找到了期望中的聚类)的分数为1.
其实,用这种方法评估聚类时,一个常见的错误是使用accuracy_score(之前在监督学习中,用于分类器评分),而不是adjusted_rand_score或者其它聚类指标。使用精度的问题在于,它要求分配的簇标签与真实值完全匹配。但簇标签本身毫无意义——唯一重要的是哪些点位于同一个簇中。
在没有真实值的情况下评估聚类
我们刚刚展示了一种评估聚类算法的方法,但在实践中,使用诸如ARI之类的指标有一个很大的问题。在应用聚类算法时,通常没有真实值来比较结果。如果我们知道了数据的正确聚类,那么可以使用这一信息构建一个监督模型(比如分类器)。因此,使用类似ARI和NMI的指标通常仅有助于开发算法,但对评估应用是否成功没有帮助。
有一些聚类的评分指标不需要真实值,比如轮廓系数。但它们在实践中的效果并不好。轮廓分数计算一个簇的紧致度,其值越大越好,最高分数为1.虽然紧致的簇很好,但紧致度不允许复杂的形状。
接下来,我们李勇轮廓分数在make_moons数据集上比较k均值,凝聚聚类和DBSCAN:
1 | |
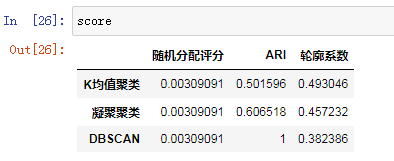
如你所见,k均值的轮廓分数最高,尽管我们可能更喜欢DBSCAN的结果:
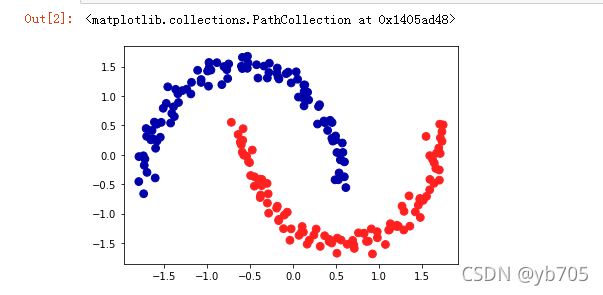
对于评估聚类,稍好的策略是使用基于鲁棒性的聚类指标,这种指标先向数据中添加一些噪声,或者使用不同的参数设定,然后运用算法,并对结果进行比较。其思想是,如果许多算法参数和许多数据扰动返回相同的结果,那么它很可能是可信的。
即使我们得到一个鲁棒性很好的聚类或者非常高的轮廓分数,但仍然不知道聚类中是否有任何语义含义,或者聚类是否反应了数据中我们感兴趣的某个方面。要想知道聚类是否对应于我们感兴趣的内容,唯一的办法就是对簇进行人工分析。
总结
其实,聚类的应用与评估是一个非常定性的过程,通常在数据分析的探索阶段很有帮助。
我们在前面分别学习了三种聚类算法:DBSCAN,k均值聚类,凝聚聚类。这三种算法都可以控制聚类的粒度。k均值和凝聚聚类允许你指定想要的簇的数量,而DBSCAN允许你用eps参数定义接近程度,从而间接影响簇的大小。三种方法都可以用于大型的现实世界数据集,都相对容易理解,也都可以聚类成多个簇。
当然,分解(PCA,NMF),流形学习与聚类一样,都是加深数据理解的重要工具,在没有监督信息的情况下,也是理解数据仅有的方法。即使在监督学习中,探索性工具对于更好地理解数据性质也很重要。通常来说,很难量化无监督算法的有用性,但这不应该妨碍你使用它们来深入理解数据。
有很多地方做的不是很好,欢迎网友来提出建议,也希望可以遇到些朋友来一起交流讨论。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!