k临近算法-回归
基本概念
先简单介绍一下机器学习里面的两个概念
1.分类与回归
分类模型和回归模型本质一样,分类模型是将回归模型的输出离散化。
一般来说,回归问题通常是用来预测一个值,如预测房价、未来的天气情况等等,例如一个产品的实际价格为500元,通过回归分析预测值为499元,我们认为这是一个比较好的回归分析。回归是对真实值的一种逼近预测。
分类问题是用于将事物打上一个标签,通常结果为离散值。例如判断一幅图片上的动物是一只猫还是一只狗。分类并没有逼近的概念,最终正确结果只有一个,错误的就是错误的,不会有相近的概念。
简言之:
定量输出称为回归,或者说是连续变量预测,预测明天的气温是多少度,这是一个回归任务
定性输出称为分类,或者说是离散变量预测,预测明天是阴、晴还是雨,就是一个分类任务
2.拟合
泛化:如果一个模型能够对没见过的新数据作出准确预测,我们就能够说它能够从训练集泛化到测试集
拟合:模型是否可以很好的描述某些样本,并且有较好的泛化能力
欠拟合:测试样本的特性没有学到,或模型过于简单无法拟合
过拟合:太过贴近于训练数据的特性,在训练集上优秀,但在测试集上不行,不具有泛化性
算法简介
KNN回归
KNN算法不仅可以用于分类,还可以用于回归。通过找出一个样本的k个最近邻居,将这些邻居的某个(些)属性的平均值赋给该样本,就可以得到该样本对应属性的值。
knn分类实操可以参考这一篇文章:k邻近算法-分类实操
数据来源
鳄梨单价预测(Kaggle):#https://www.kaggle.com/neuromusic/avocado-prices
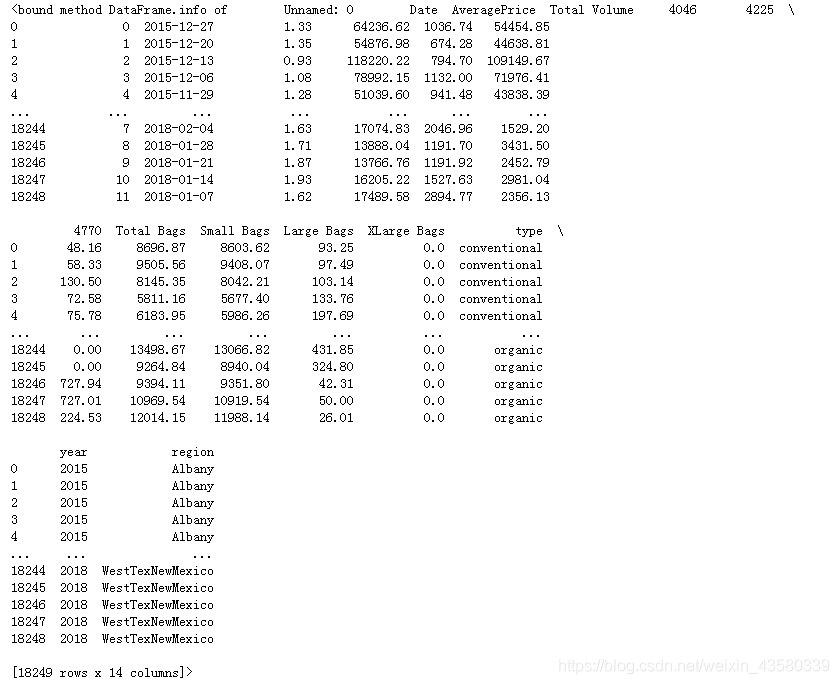
该数据包含2017年到2019年的鳄梨单价,每次出售的重量,鳄梨种类,产地等信息。
Tips:4046,4225,4770是国外进口水果的plu码,plu四位码代表鳄梨的产地,种类,大小等水果信息,所以4046,4225,4770就是代表三种鳄梨。有一说一,平常买水果还真没注意到这个。又知道了一个无用的小知识。
数据挖掘
1.导入第三方库
1 | |
老规矩,上来先依次导入建模需要的各个模块,除了前四个库是数据挖掘必要的第三方库之外,重点说一下r2_score:
sklearn.metrics.r2_score(y_true, y_pred, sample_weight=None, multioutput=’uniform_average’)
y_true:观测值
y_pred:预测值
sample_weight:样本权重,默认None
multioutput:多维输入输出,可选‘raw_values’, ‘uniform_average’, ‘variance_weighted’或None。默认为’uniform_average’;
raw_values:分别返回各维度得分
uniform_average:各输出维度得分的平均
variance_weighted:对所有输出的分数进行平均,并根据每个输出的方差进行加权。
r2_score评分是主要的回归模型评分方式,具体原理就不多做介绍了,感兴趣的朋友可以查看这篇文章:深度研究:回归模型评价指标R2_score
2.读取文件
1 | |
因为之前每次下载数据之后都要将文件转移到python根目录里面,或者到下载文件夹里面去读取,很麻烦。所以我通过winreg库,来设立绝对桌面路径,这样只要把数据下载到桌面上,或者粘到桌面上的特定文件夹里面去读取就好了,不会跟其它数据搞混。
3.清洗数据
1 | |
这里我们选择2017年的数据作为建模数据。(有的时候数据量太多反而会造成一些噪音干扰)
1 | |
因为type和region的文本数据有点复杂,所以利用replace函数替换成数字来代表不同的品种和产地。其实这个替换并没有什么用,只是博主单纯地看不习惯文本数据而已。
因为数据中的特征值Total Bags=Small Bags+Large Bags,XLarge Bags=0,且region,type皆与4位plu码有属性重合的情况,所以为了避免出现过拟合,我这里只选取AveragePrice,Total Volume,4046,4225,4770,Small Bags,Large Bags进行预测建模。
4.建模
1 | |
划分列索引为特征值和预测值,并将数据划分成训练集和测试集。
1 | |
引入knn算法,并将算法中的邻居值设为1,进行建模后,对测试集进行精度评分,得到的结果如下:
可以看到,该模型的精度为50%左右。
5.简单的调参
之前设立的邻居参数为1,接下来依次测试不同的参数,看看最优的邻居参数是多少。
1 | |
结果如下: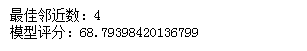
可以看出在邻近数依次选择1~100的过程中,最佳邻近参数为4;模型的最佳精度评分是68分。(可以看到分数很低,博主认为有可能是算法本身的原因。毕竟是一个简单的算法,而不像森林或者树回归算法一样,可以调整权重等其它参数。)
6.总结
1.随着邻近参数的变化,模型精度也会跟随变化,并呈现一定的规律的规律: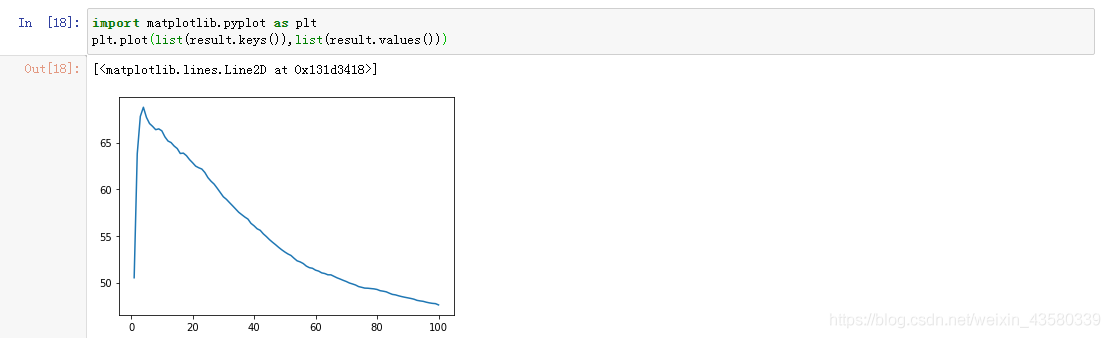
对于同一个数据集,随着邻近参数的逐渐增加,模型精度往往会到达一个临界点,之后便会逐渐降低。其他的knn回归模型也会呈现这种情况,有兴趣的朋友可以自行检验一下。
2.回归类算法是预测连续值的算法,如果打算通过对预测标签进行分箱(pd.cut),来对预测标签进行变化范围的预测是行不通的。ps:博主已经尝试过,会报错误。
3.对于不同类型的数据要选择不同类型的算法,每个算法都有各自的优缺点,并没有可以解决所有问题的算法,所以在以后的建模中不要钻牛角尖,要注意选择。
有很多地方做的不是很好,欢迎网友来提出建议,也希望可以遇到些朋友来一起交流讨论。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!