决策树算法-单棵树(下)
序
在上篇的文章决策树算法之讲解实操(上)当中,我们主要了解了决策树的算法原理,实际应用,以及简单介绍了下决策树的复杂度参数。而这篇我们主要讲解决策树的分析可视化,特征值重要程度,以及讨论回归决策树。
决策树的分析与可视化
树的可视化有助于深入理解算法是如何进行预测的,也是易于向非专家解释的机器学习算法的优秀示例。我们可以利用tree模块的export_graphviz函数来将树可视化。这个函数会生成一个.dot格式的文件,这是一种用于保存图形的文本文件格式。我们设置为结点添加颜色的选项,颜色表示每个结点中的多数类别,同时传入类别名称和特征名称,这样可以对树进行标记,代码如下:
1 | |
PS:数据是来自于上一篇文章决策树算法之讲解实操(上)当中的红酒数据,不了解的朋友可以去看一看,具体的我就不在这里多讲了。
为了让图形更容易观察,我这里将树的深度调整为了3。当然,在实际调参过程中,为了保证模型的精度,树的深度肯定不只是3。
接下来我们利用graphviz模块读取这个文件并将其可视化(当然你也可以用其它可以读取.dot文件的程序)。
与其它的第三方库的安装不同,要想使用graphviz模块,还需要再单独下载安装,并且配置环境变量,具体安装流程可以参考这篇文章:Graphviz安装(ps:安装graphviz,并且配置完环境变量后,建议重启一下python程序,不然没法马上识别出来dot文件)。
那么在安装好了之后,运行下面的代码就能可视化决策树了:
1 | |
结果如下所示: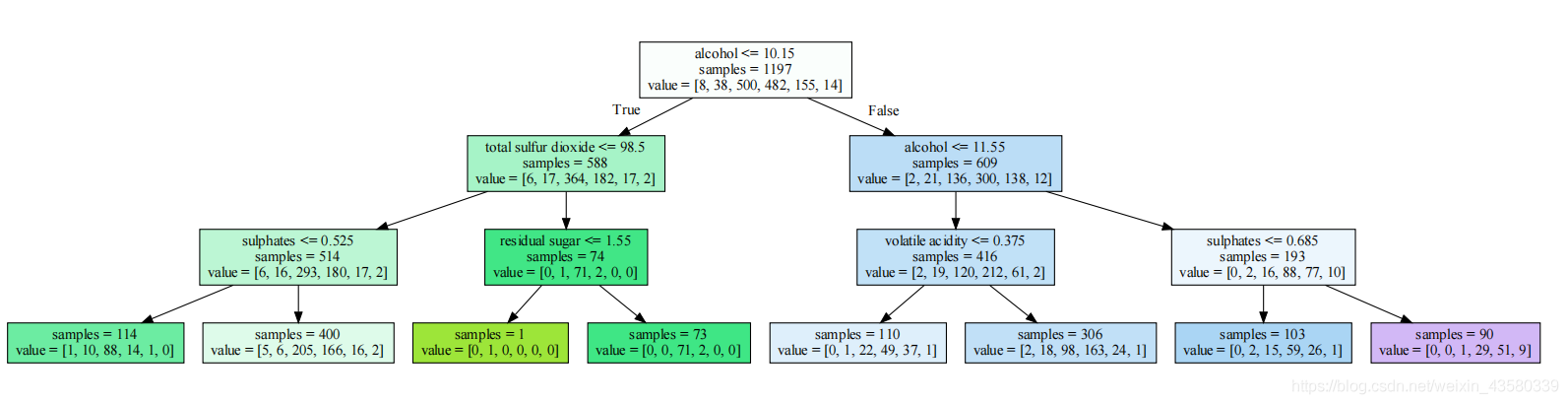
实际上,即使这棵树的深度只有3层,看起来也还是有点大的。而深度更大的树(深度为10并不罕见)更加难以理解。这个时候,就有一种观察法可以提升效率了,那就是找出大部分数据的实际路径。譬如在上面的图形中,寻找samples占比最高的数据路径。像是第三层的samples=514,samples=416这两个结点,然后顺着这两个结点继续向下观察samples=400,samples=306这两个结点。几乎大部分数据都是顺着流程进入这几个结点,而其它叶结点都只包含很少的样本。
树的特征重要性
实际上就算将整棵树可视化进行观察,也是非常费劲的。所以除此之外,我们还可以利用一些有用的属性来总结树的工作原理。其中最常用的就是特征重要性,它为每个特征对树的决策的重要性进行排序。对于每个特征来说,它都是一个介于0到1之间的数字,其中0表示“根本没用到”,1表示”完美预测目标值“,而特征重要性的求和始终为1。代码如下所示:
我们可以将特征重要性可视化: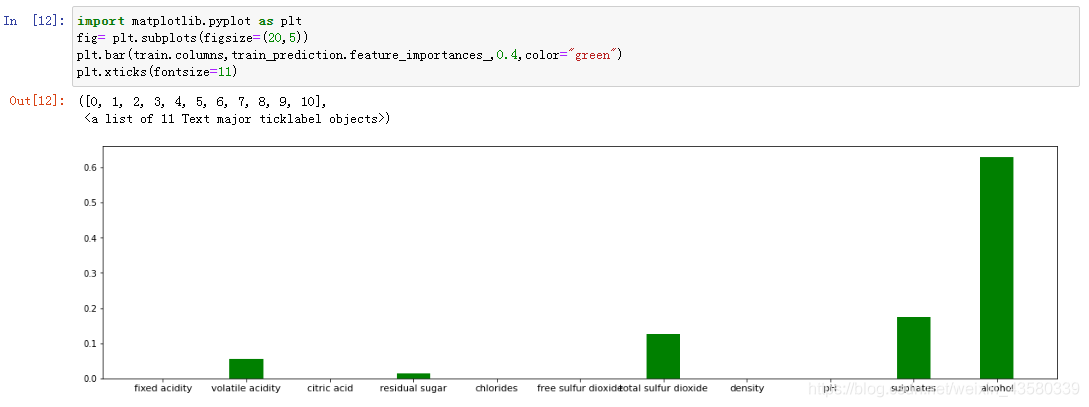
我们可以看到,在这些特征当中,酒精含量(alcohol)是影响红酒质量的最重要的因素。
但是如果某个特征的feature_importance_很小,并不能说明这个特征没有提供任何信息。只能说明该特征没有被树选中,可能是因为另一个特征也包含了同样的信息。
与线性模型的系数不同,特征重要性始终为正数,也不能说明该特征对应哪个类别。特征重要性告诉我们酒精含量(alcohol)特征很重要,但并没有告诉我们含量大表示红酒质量高或者是低。事实上,在特征和类别之间可能没有这样简单的关系。
回归决策树
虽然我们主要讨论的是用于分类的决策树,但对用于回归的决策树来说,所有内容都是类似的。在DecisionTreeRegressor中实现,回归树的用法和分析与分类树非常类似。但在将基于树的模型用于回归时,我们想要指出它的一个特殊性质:那就是DecisionTreeRegressor(以及其他所有基于树的回归模型)不能外推,也不能在训练数据范围之外进行预测。
我们通过一个简单的对数求和例子来更详细地研究这点。代码如下所示:
1 | |
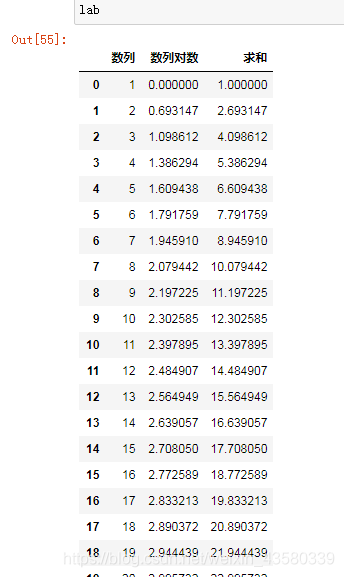
实际上,上述数据集的设定就是:一列是顺序数列,一列是顺序数列的对数,还有一列就是前两列的求和,它的回归线就是:y=x+log(x),如下图所示: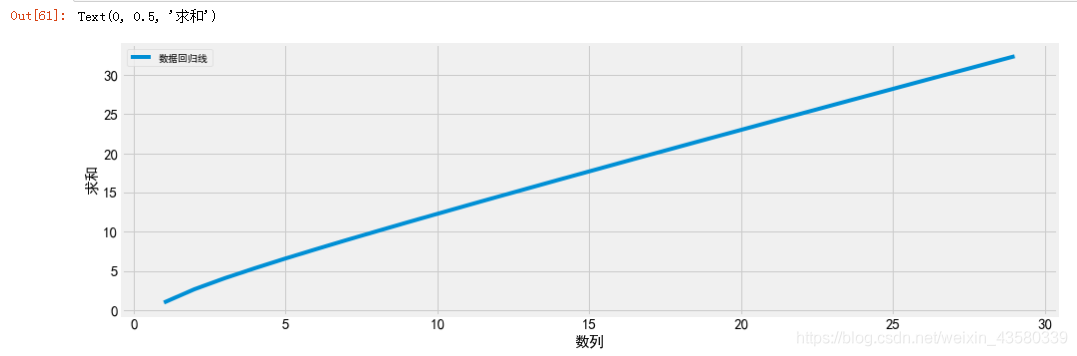
如果是利用线性模型来去做回归预测是非常容易的,并且模型精度会很高,这里就不再赘述了。那么接下来我们用决策树的回归算法进行建模,并分别对训练数据集内和训练数据集外的数据进行预测,代码如下所示:
1 | |
将预测结果可视化:
1 | |
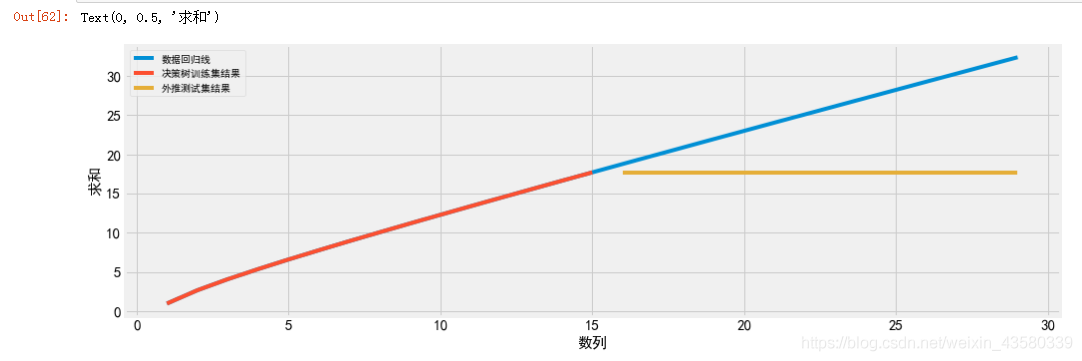
可以看出树模型完美预测了训练数据集(红线与蓝线重合的部分)。由于我们没有限制树的复杂度,因此它记住了整个数据集。但是,一旦输入超出训练集之外的数据,模型就只能持续预测最后一个已知数据点(黄线)。树不能在训练数据的范围之外生成”新的“响应,所有基于树的回归模型都有这个缺点。
实际上,利用基于树的模型可以做出非常好的预测。上述例子的目的并不是说明决策树是一个不好的模型,而是为了说明树在预测方式上的特殊性质。
小结
如上篇文章所述,控制决策树模型复杂度的参数是预剪枝参数,它在树完全展开之前停止树的构造。通常来说,选择一种预剪枝策略(设置max_depth,max_leaf_nodes或min_samples_leaf)足以防止过拟合。
与前面讨论过的许多算法相比,决策树有两个优点:一是得到的模型很容易可视化,非专家也很容易理解(至少对于较小的树来说);二是算法完全不受数据缩放影响。由于每个特征被单独处理,而且数据的划分也不依赖于缩放,因此决策树算法不需要特征预处理,比如归一化或标准化。特别是特征的尺度不一样时或者二元特征和连续特征同时存在时,决策树效果很好。
决策树的主要缺点在于,即使做了预剪枝,它也会经常过拟合,泛化能力较差。因此,在大多数应用中,往往绘制用集成方法来替代单颗决策树。集成方法我们会在以后进行介绍。
有很多地方做的不是很好,欢迎网友来提出建议,也希望可以遇到些朋友来一起交流讨论。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!